Профилирование Go: основы и практика
23 апреля 2020 г. Profiling Pprof Benchmark Ab Cpu Allocation Remote

Go имеет богатые инструменты профилирования с самого начала — пакет pprof и go tool pprof. Давайте обсудим, почему профилирование полезно, как с ним работать и что нового в этой области.
Почему профилирование полезно
При использовании отладчика можно найти логические ошибки. Это базовая отладка.
Программа может работать логически правильно, но могут появиться следующие побочные эффекты:
- долгое выполнение в некоторых случаях;
- высокое потребление памяти;
- высокая нагрузка на процессор;
Всё вышеперечисленное не является ошибкой, пока программа продолжает функционировать. Однако высокое потребление ресурсов дорого обходится владельцам сервисов — для поддержки таких сервисов время от времени требуются новые аппаратные ресурсы.
Если внешняя нагрузка на сервис увеличивается, все эти “слабые места” могут стать причиной неожиданных сбоев — если у сервиса закончится память, он просто завершит работу; если не хватает CPU, сервер станет недоступен даже для SSH-подключений.
Профилировщик чрезвычайно полезен для проверки программы с целью найти такие проблемы.
Какой инструмент подходит для профилирования
Стандартный инструмент профилировщика Go — pprof — отличный. Давайте использовать pprof.
Как профилировать
Профилирование состоит из двух действий:
- сбор данных профилирования из сервиса;
- визуализация и анализ данных;
Для сбора данных профилирования следует:
- реализовать ручной сбор метрик и экспорт с помощью пакета
pprof, или - запустить endpoint
net/http/pprof, который предоставляет экспорт данных профилирования;
Для начинающих проще использовать вариант 2.
Чтобы запустить endpoint профилирования, следует:
- добавить
import _ "net/http/pprof"в код программы; - если в программе уже запущен сервер
net/http— больше ничего не требуется; - если нет, следует добавить код запуска сервера:
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
Согласно исходному коду net/http/pprof, становится очевидным, что делает этот импорт:
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}
Пример профилирования
Я собираюсь профилировать веб-сервис, запущенный на localhost:8090.
Я импортировал net/http/pprof и добавил запуск HTTP-сервера.
Получение данных профиля
Сначала я собираюсь нагрузить мой сервис с помощью инструмента Apache Benchmark (ab):
ab -n 1000 -c10 http://localhost:8090/
ab выводит свою собственную статистику о времени запросов, но сейчас она мне не нужна. Я собираюсь анализировать данные профилирования.
Пока сервис под нагрузкой, я запрашиваю данные профилирования CPU на следующие 5 секунд:
curl http://localhost:6060/debug/pprof/profile?seconds=5 > ./profile
В результате файл профиля загружается. Это всё для получения данных профилирования. Давайте проанализируем их.
Анализ профиля CPU
Давайте откроем данные профилирования, которые я только что загрузил, с помощью go tool pprof:
go tool pprof ./profile
Type: cpu
Time: Apr 19, 2020 at 9:28pm (+03)
Duration: 5.40s, Total samples = 400ms ( 7.41%)
Entering interactive mode (type "help" for commands, "o" for options)
Мы можем вывести данные в виде изображения:
(pprof) web
Это требует установки инструмента Graphviz.
В результате я получил схему функций, где самые долго работающие функции больше других.
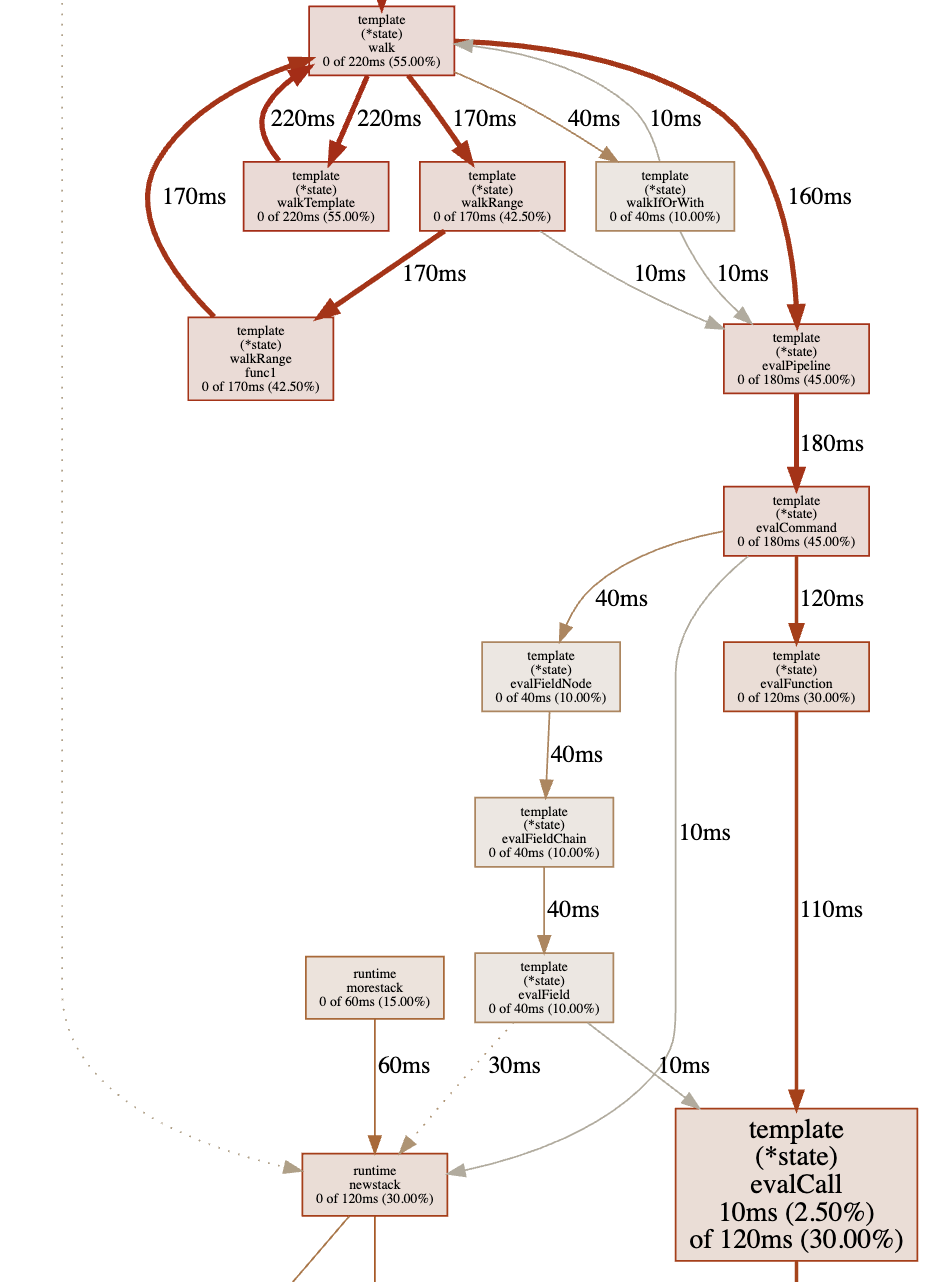
Как мы видим, больше всего времени тратится на вызовы пакета html/template, что вовлекает нас в исходники Go. Это стандартное поведение профилировщика — неважно, из кода приложения функция или из исходников Go.
Давайте вернёмся к терминалу pprof и выведем топ-15 функций по времени работы:
(pprof) top15
Showing nodes accounting for 0, 0% of 400ms total
Showing top 15 nodes out of 147
flat flat% sum% cum cum%
0 0% 0% 260ms 65.00% net/http.(*conn).serve
0 0% 0% 240ms 60.00% github.com/labstack/echo.(*Echo).ServeHTTP
0 0% 0% 240ms 60.00% github.com/labstack/echo.(*Echo).ServeHTTP.func1
0 0% 0% 240ms 60.00% github.com/labstack/echo.(*Echo).add.func1
0 0% 0% 240ms 60.00% github.com/labstack/echo.(*context).Render
0 0% 0% 240ms 60.00% github.com/labstack/echo/middleware.AddTrailingSlashWithConfig.func1.1
0 0% 0% 240ms 60.00% github.com/labstack/echo/middleware.CORSWithConfig.func1.1
0 0% 0% 240ms 60.00% net/http.serverHandler.ServeHTTP
0 0% 0% 220ms 55.00% html/template.(*Template).Execute
0 0% 0% 220ms 55.00% text/template.(*Template).Execute
0 0% 0% 220ms 55.00% text/template.(*Template).execute
0 0% 0% 220ms 55.00% text/template.(*state).walk
0 0% 0% 220ms 55.00% text/template.(*state).walkTemplate
Рендеринг шаблонов также в топе.
Мы можем вывести исходный код любой функции, чтобы увидеть, какая часть занимает какое время:
(pprof) list text/template.\(\*state\).walk$
Total: 400ms
ROUTINE ======================== text/template.(*state).walk in /usr/local/Cellar/go/1.14/libexec/src/text/template/exec.go
0 830ms (flat, cum) 207.50% of Total
. . 250: s.at(node)
. . 251: switch node := node.(type) {
. . 252: case *parse.ActionNode:
. . 253: // Do not pop variables so they persist until next end.
. . 254: // Also, if the action declares variables, don't print the result.
160ms 160ms 255: val := s.evalPipeline(dot, node.Pipe)
. . 256: if len(node.Pipe.Decl) == 0 {
20ms 20ms 257: s.printValue(node, val)
. . 258: }
. . 259: case *parse.IfNode:
40ms 40ms 260: s.walkIfOrWith(parse.NodeIf, dot, node.Pipe, node.List, node.ElseList)
. . 261: case *parse.ListNode:
. . 262: for _, node := range node.Nodes {
220ms 220ms 263: s.walk(dot, node)
. . 264: }
. . 265: case *parse.RangeNode:
170ms 170ms 266: s.walkRange(dot, node)
. . 267: case *parse.TemplateNode:
220ms 220ms 268: s.walkTemplate(dot, node)
. . 269: case *parse.TextNode:
. . 270: if _, err := s.wr.Write(node.Text); err != nil {
. . 271: s.writeError(err)
. . 272: }
. . 273: case *parse.WithNode:
Выводы:
- здесь есть рекурсия (строка 263);
- есть вызовы пакета
reflect, которые считаются “тяжёлыми”; - я не могу изменить исходный код Go.
Но я могу изменить код моего сервиса, который вызывает стандартные пакеты Go. В настоящее время в моём сервисе есть вызов шаблона при каждом запросе клиента. Однако шаблоны статичны и постоянны. Результат вызова шаблона зависит от данных запроса.
Я собираюсь кэшировать результат вызова шаблона — рендеринг будет вызываться один раз для каждой комбинации данных запроса. При первом запросе в кэше нет данных. В этом случае выполняется вызов шаблона. Результат вызова шаблона сохраняется в кэш с ключом, сгенерированным из данных запроса. При каждом запросе сервис проверяет, есть ли данные в кэше по определённому ключу. И сервис использует кэшированные данные, если они есть.
Я изменил код сервиса и снова запустил профилирование. Результаты ниже:
(pprof) top15
Showing nodes accounting for 90ms, 50.00% of 180ms total
Showing top 15 nodes out of 78
flat flat% sum% cum cum%
0 0% 0% 100ms 55.56% net/http.(*conn).serve
90ms 50.00% 50.00% 90ms 50.00% syscall.syscall
0 0% 50.00% 60ms 33.33% bufio.(*Writer).Flush
0 0% 50.00% 60ms 33.33% internal/poll.(*FD).Write
0 0% 50.00% 60ms 33.33% net.(*conn).Write
0 0% 50.00% 60ms 33.33% net.(*netFD).Write
0 0% 50.00% 60ms 33.33% net/http.(*response).finishRequest
0 0% 50.00% 60ms 33.33% net/http.checkConnErrorWriter.Write
0 0% 50.00% 60ms 33.33% syscall.Write
0 0% 50.00% 60ms 33.33% syscall.write
0 0% 50.00% 40ms 22.22% runtime.findrunnable
0 0% 50.00% 40ms 22.22% runtime.mcall
0 0% 50.00% 40ms 22.22% runtime.schedule
0 0% 50.00% 30ms 16.67% github.com/labstack/echo.(*Echo).Start
Как мы видим, теперь в топе есть вызовы syscall.Write. И вызовы шаблонов больше не в топе.
Это отлично! Потому что цель наших изменений — сделать поведение приложения как можно быстрее, чтобы базовые операции ОС — чтение и отправка данных по сети — оказались наверху.
Теперь давайте сравним результаты ab — строку “Requests per second”:
- До: Requests per second: 14.13 [#/sec] (mean)
- После: Requests per second: 638.38 [#/sec] (mean)
Как мы видим, сервис теперь работает намного быстрее.
Заключение
Можно открыть endpoint net/http/pprof в браузере. Это тот же endpoint, который мы использовали через curl для получения данных профилирования. Страница выглядит следующим образом:
/debug/pprof/
Доступные типы профилей:
| Count | Profile |
|---|---|
| 9 | allocs |
| 0 | block |
| 0 | cmdline |
| 9 | goroutine |
| 9 | heap |
| 0 | mutex |
| 0 | profile |
| 18 | threadcreate |
| 0 | trace |
Мы можем получить другие метрики:
- о выделении памяти в каждой функции;
- о вызовах
sync.Mutex; - о создании новых потоков;
- и многие другие.
Наиболее полезными здесь являются профилирование CPU и памяти.
Удалённое профилирование
Endpoint профилирования pprof, который мы включили выше, может быть доступен из внешней сети:
// сервер слушает на всех сетевых интерфейсах (не только localhost), порт 6060
log.Println(http.ListenAndServe(":6060", nil))
Но следует быть осторожным и ограничить доступ только для разработчиков!
Очень полезно профилировать продакшн-сервисы, но endpoint профилирования, доступный для внешних клиентских запросов, является уязвимостью — вызовы профилировщика замедляют сервис.
Что нового в теме профилирования
Подход предоставления данных профилирования покрывает любую ситуацию и не будет изменяться.
Однако анализ данных здесь можно улучшить. Было выпущено много инструментов визуализации.
Для меня наиболее полезным является flamegraph.
В IDE GoLand есть возможности отображения данных профилирования Go. Но go tool pprof также предоставляет богатую функциональность фильтрации и сортировки. В этой статье такая функциональность не рассматривается, но есть примеры в блоге Go.
Похожие статьи
Принципы работы типа slice в GO

В блоге Go описывается, как использовать срезы. Давайте посмотрим на внутреннее устройство срезов.
Read More → Slice Allocation Sources